15 mai 2024
Christopher Kermorvant ; Marion Charpier
Détection automatique d’éléments iconographiques dans les images : principes et mise en œuvre
3 types de modèle
- détection, c’est le moins fin, il n’est pas nécessaire de créer une ontologie, on cherche des objets, sans avoir besoin de les classifier
- classification : on attribut une étiquette ou une classe à une image ou à une région spécifique de l’image
- segmentation : encore plus fin, on divise une image en segment ou en région en fonction de certaine propriété
En utilisant SAM on peut segmenter une image, récupérer les coordonées et s’en servir pour les classifier. La robustesse d’un modèle est calculer avec un metric l’intersection over union (IOU). Il s’agit du taux de chevauchement entre la boite d’annotation et la vérité de terrain. En dessous de 0.5 (50% de superposition des deux boites) on considère que la prédiction est fausse. Mais attention :
- vrai positif (TP) : un objet dont la classe et la detection sont bonnes
- faux positif (FP) : détection d’une classe correcte mais mal positionné
- faux négatif (FN) : rien n’est bon dans la détection
ces trois indicateurs permettent de calculer le rappel, la précision et le score F1 Un modèle parfait à une score F1 = 1.
Une autre metric intéressante pour évaluer un modèle est la matrice de confusion.
Comment choisir un modèle
Prendre en compte précision et performance, complexité et taille du modèle (demande de ressources computationnelles), robustesse aux variations, flexibilité et modularité.
Détection automatique d’objets dans les images avec YOLO
Principe de l’apprentissage automatique (Machine learning)
Comment faire exécuter une tâche à un ordinateur La première solution c’est d’écrire un programme : un expert explique à un développeur la tâche à réaliser.
La seconde solution c’est de faire apprendre la machine : avec le ML on a toujours un expert qui prend des exemples annotés, un ingénieur ML va nourrir un apprentissage à partir des exemples annotés pour créer un modèle, qui sera capable de rédiger un programme.
avec la programmation le programme est écrit par un dev, l’expert doit pouvoir explicité les règles, il faut un programme par tâche, en cas d’erreur il faut modifier le programme Avec l’apprentissage automatique, le programme est écrit par la machine, l’expert doit annoter des exemple, un seul programme d’apprentissage pour plusieurs tâche et si on a des erreurs, il suffit de donner de nouveaux exemples. le pipeline est le suivant :
Exemples annotés -> apprentissage -> modèle
↓
Exemples à traiter -> programme -> exécution -> prédictionLes exemples définissent le programme : l’annotation est la phse la plus importante. Comment bien choisir les exemple : il faut constituer un échantillonage aléatoire et représentatif. Il faut également annoter come ce que l’on souhaite obtenir en prédiction.
L’objectif est d’apprendre à généraliser pour prédire sur des exemples nons vus pendant l’apprentissage. : il faut 3 éléments
- un échantillon pour apprendre (train test)
- un echantillon pour vérifier le modèle généralisé (validation set)
- un échantillon pour évaluer le modèle (test set) Ces 3 ensembles doivent être repésentatifs, aléatoires et disjoints.
NB : avec YOLO assez peu de données sont nécessaires pour obtenir de bon résultat. +NB 2 : possibilité d’augmenter artificiellement les données avec les changements de perspectives par exemple, ou modification des images. mais plus efficace lorsque c’est intégrer dans un script d’apprentissage.
Entrainement d’un modèle de détection avec Arkindex
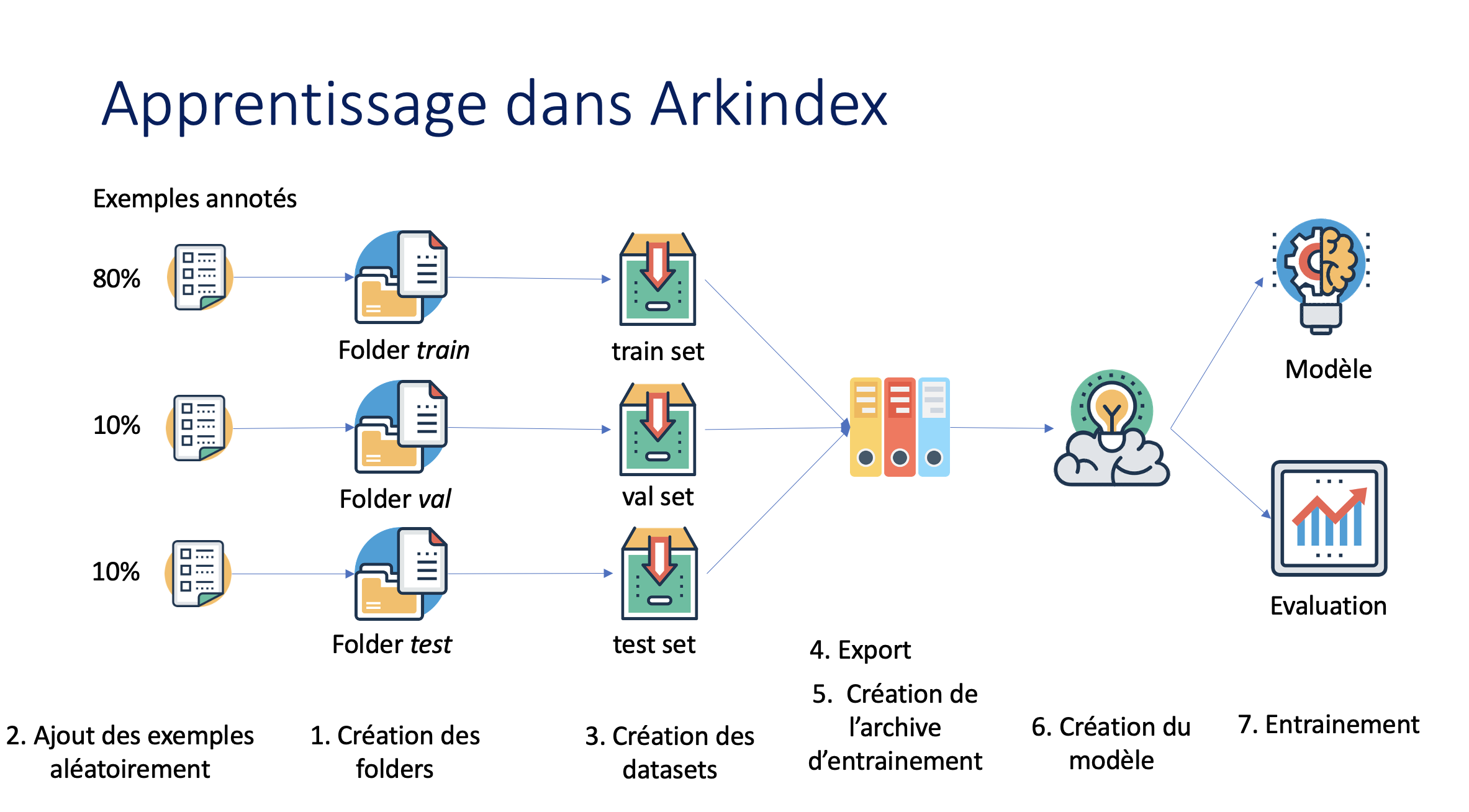
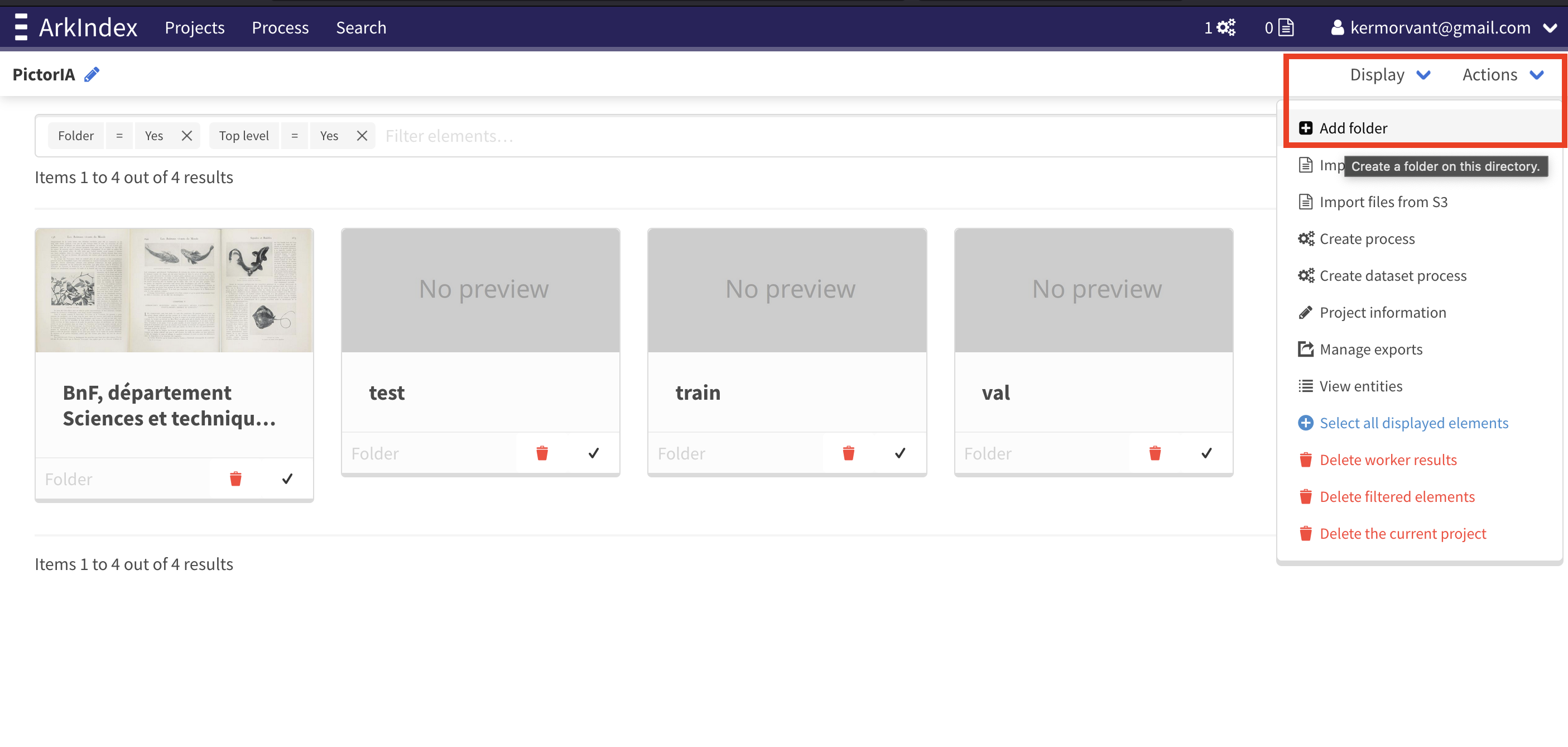
1. Créer des répertoires (folders) dans votre projet
- Naviguer dans votre projet
- Créer 3 répertoires (folders) avec les noms Train, Dev et Test
- Menu Actions->Add folder
En vidéo :
youtube S_7N3jYALtc
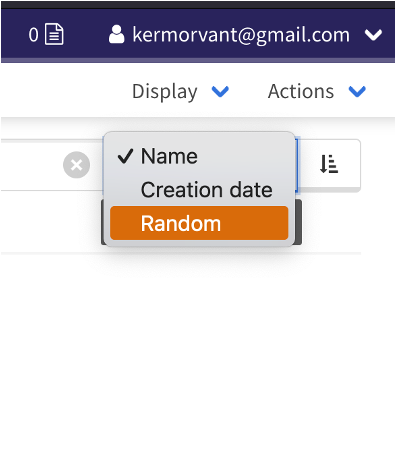
2. Répartir les exemples aléatoirement dans les répertoires train/dev/test
2.1 Utiliser la présentation Random
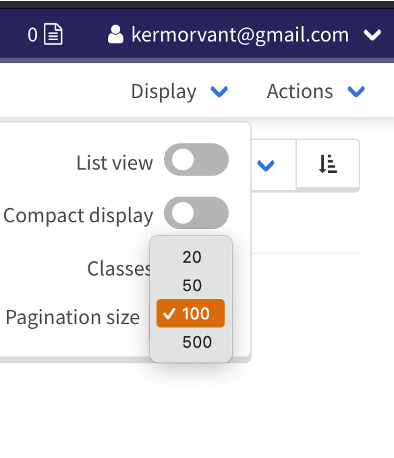
2.2 Utiliser la pagination à 100
2.3 Utiliser la sélection
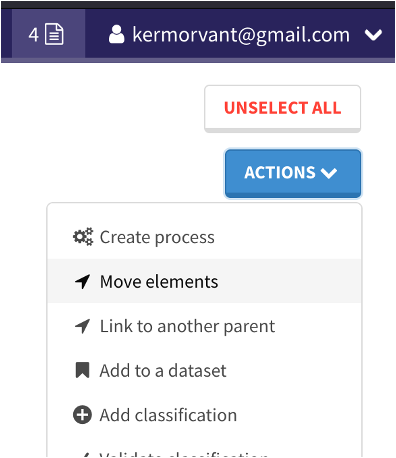
En vidéo :
youtube XOP27j-4ee4
3. Créer un dataset avec des sous-ensembles Train/Val/Test
- Menu Actions -> Project Information -> Dataset
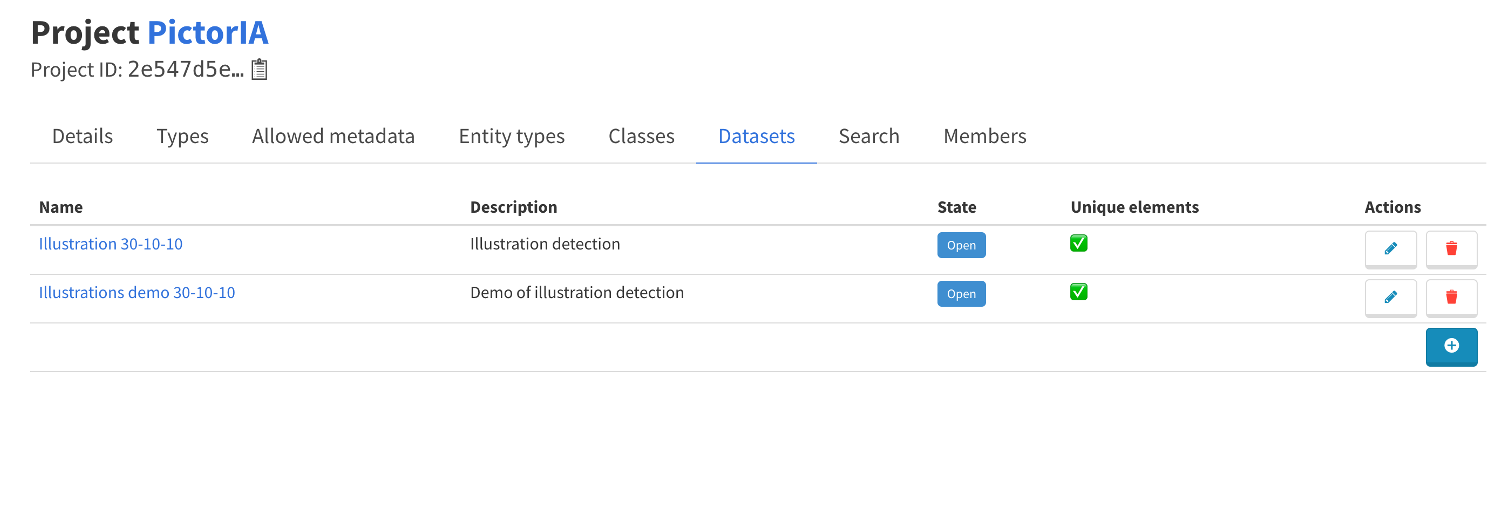
En vidéo :
youtube wkxgt9NSMXc
4. Générer l’export complet du projet
- Menu Actions -> Manage Export -> Start Export
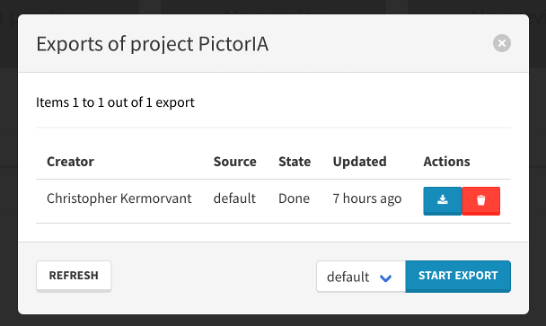
:::info Pourquoi cette étape ? Arkindex permet l’entrainement distribué (cloud, cluster) L’export et la génération de l’archive d’entrainement permettent la distribution des données :::
En vidéo :
youtube w082mRvSqEI
5. Générer l’archive d’entrainement à partir du projet
- Menu Actions -> Create Dataset process
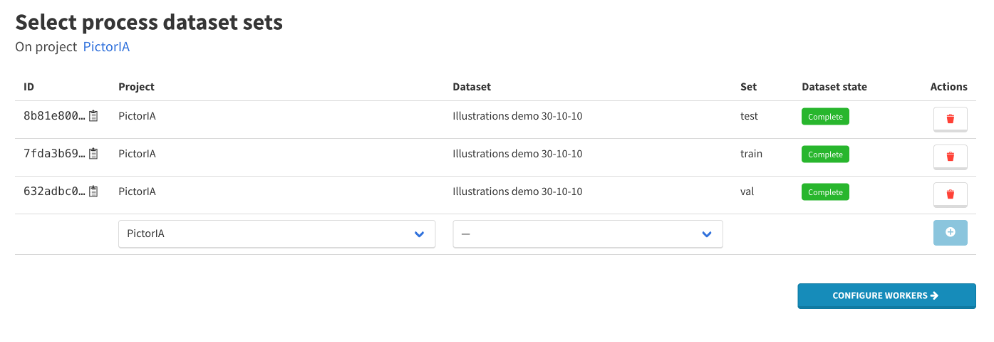
- Select « Generic Training Dataset Extractor »
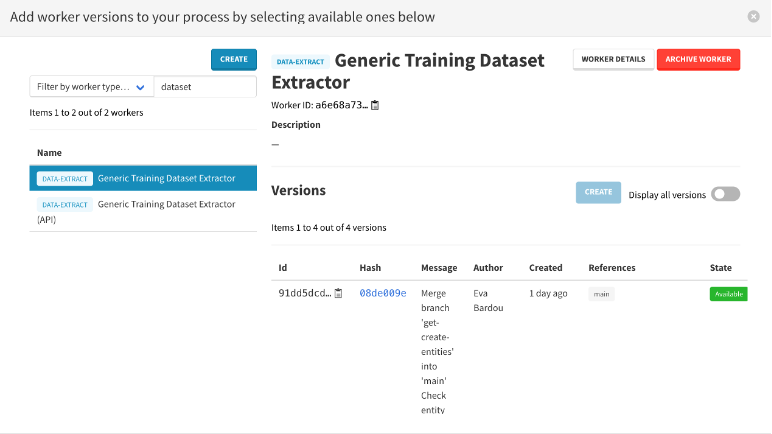
- Run Process
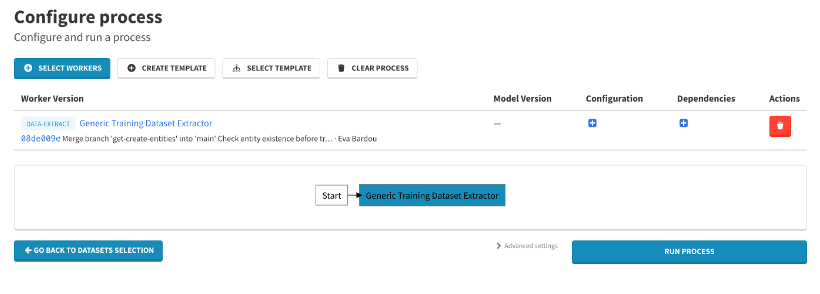
En vidéo :
youtube GLOY-Q9ekpc
6. Créer un modèle
- Menu Personnel -> Models
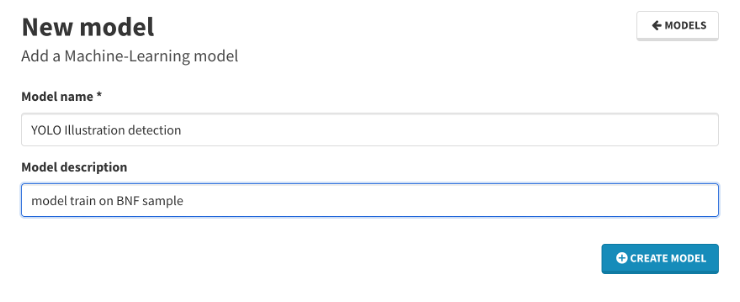
- CREATE MODEL puis renseigner les informations
En vidéo :
youtube _0B2ARsnbqo
7. Lancer l’entrainement du modèle YOLO
7.1 Menu Actions -> Create Dataset process
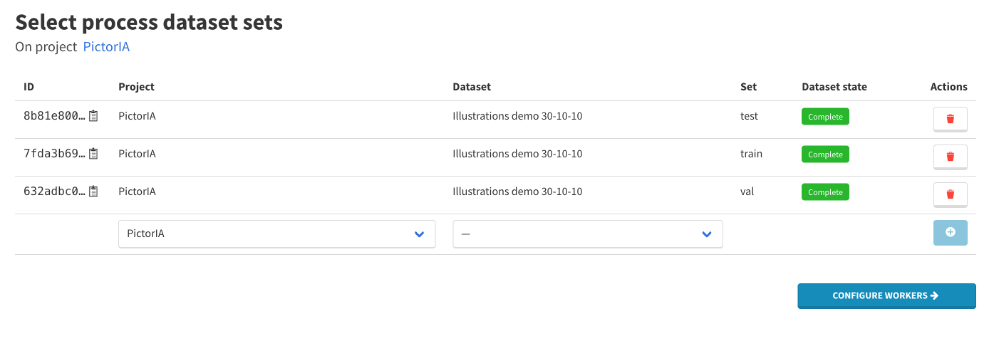
7.2. Find the YOLO Training | Detect/Segment worker
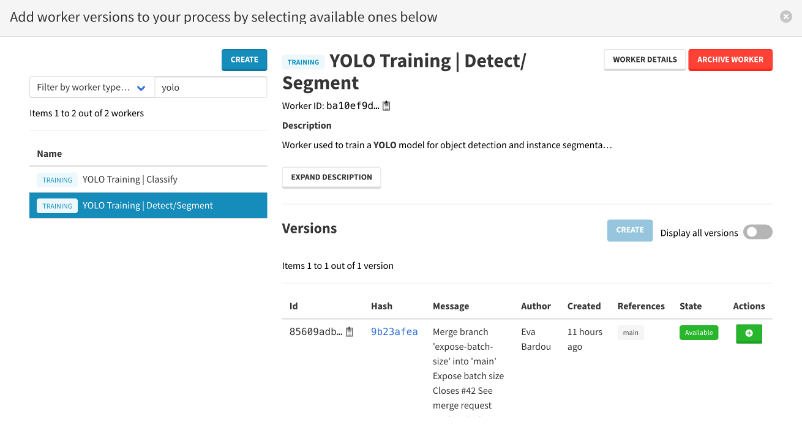
7.3 Créer une configuration d’entrainement
- Name : votre_nom YOLO illustration
- Class names to predict : illustration
- Model that will receive the new trained version : nom du modèle créé en 6.
- Number of epochs to train the model : 3
- Type of object to detect using the segmenter : bbox
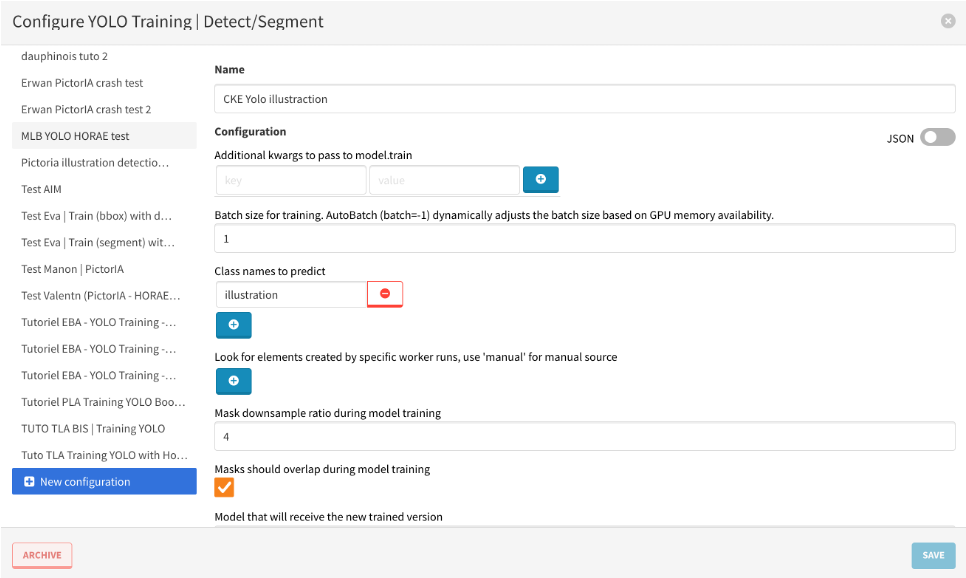
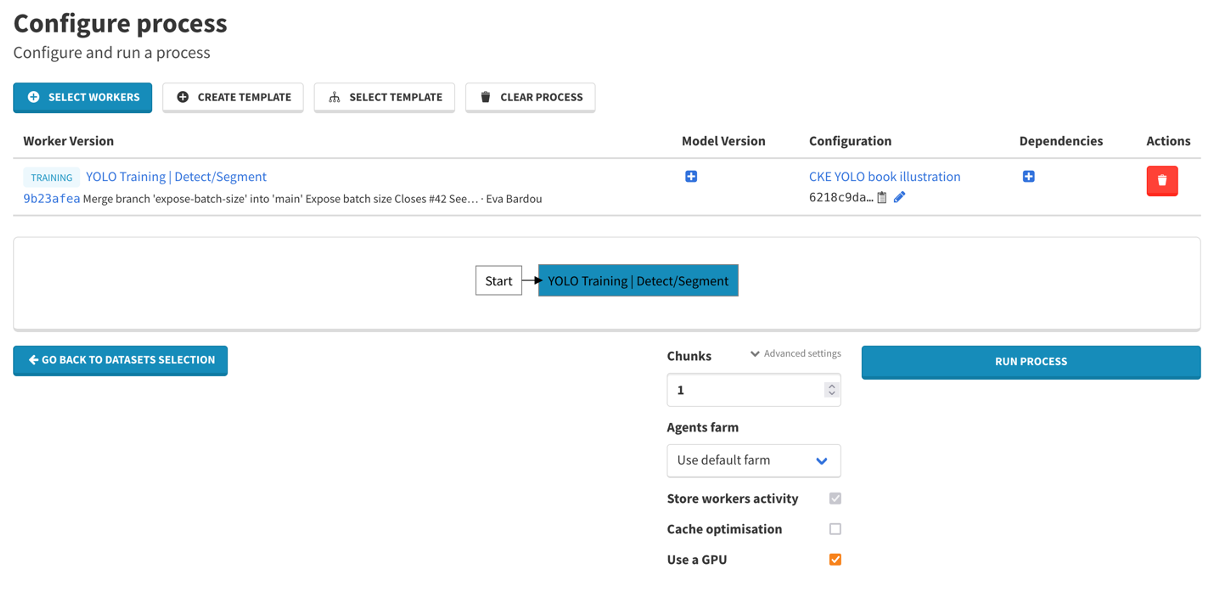
7.4 Lancer l’entrainement
- Sélectionner GPU
- RUN PROCESS
En vidéo :
youtube 9XiL9FxD31M